公司新闻
C++性能优化
摘要:性能优化不管是从方法论还是从实践上都有很多东西,本系列的文章会从C++语言本身入手,介绍一些性能优化的方法,希望能做到简洁实用。
作者:ali4846j3o
原文:http://click.aliyun.com/m/41845/
性能优化不管是从方法论还是从实践上都有很多东西,本系列的文章会从C++语言本身入手,介绍一些性能优化的方法,希望能做到简洁实用。
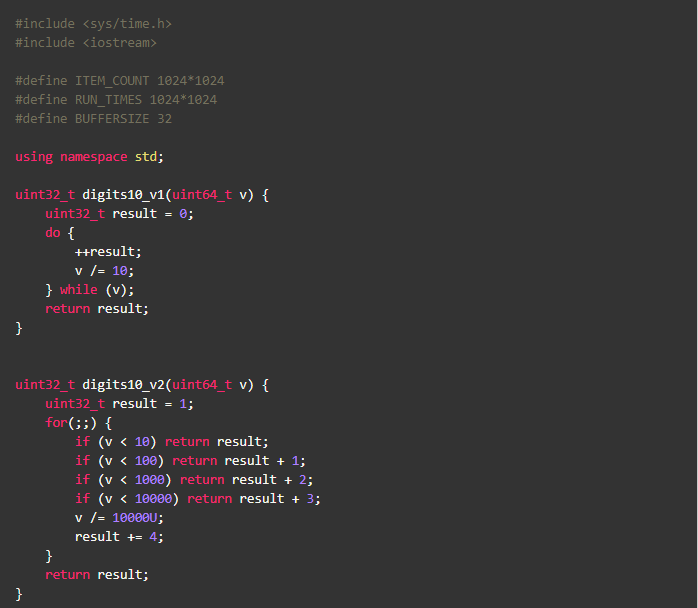
在开始本文的内容之前,让我们看段小程序:
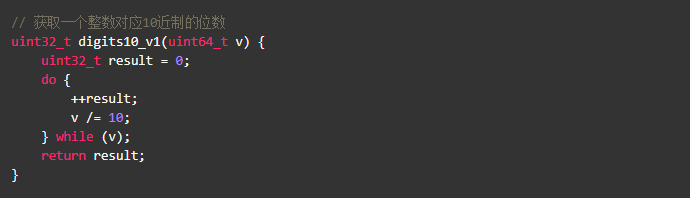
如果要对这段代码进行优化,你认为瓶颈会是什么呢?代码-g -O2后看一眼汇编:
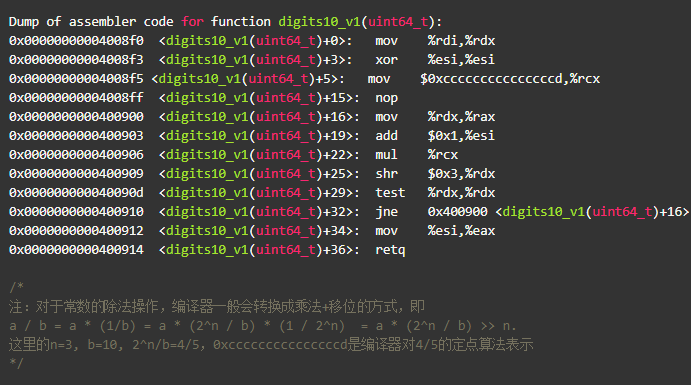
指令已经很少了,有多少优化空间呢?先不着急,看看下面这段代码
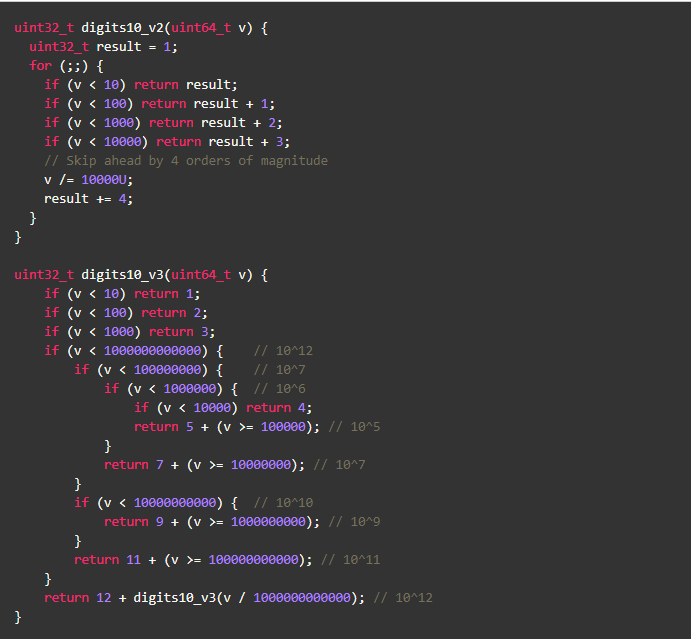
写了一个小程序,digits10_v2 比 digits10_v1快了45%, digits10_v3 比digits10_v1快了60%+。
不难看出测试结论跟数据的取值范围相关,就本例来说数值越大,提升越明显。是什么原因呢?附测试程序:
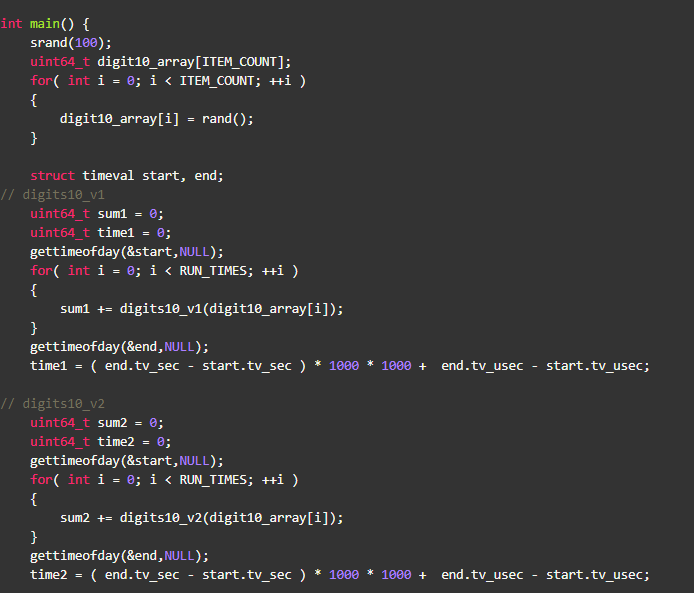
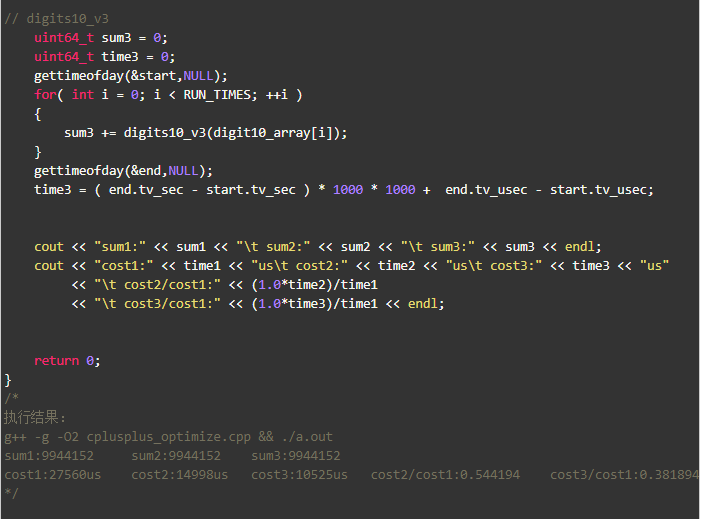
优化原因不是因为做了循环展开,而是由于不同指令本身的速度就是不一样的,比较、整型的加减、位操作速度都是最快的,而除法/取余却很慢。
下面有一个更详细的列表,为了更直观一些,用了clock cycle来衡量,不过这里的clock cycle是个平均值,不同的CPU还是稍有差异:

虽然大多数场景下,数学运算都不会有太多性能问题,但相对来说,整型的除法运算还是比较昂贵的。编译器就会利用这一特点进行优化,一般称作Strength reduction.
对于前面的例子,核心原因是digits10_v2用比较和加法来减少除法(/=)操作,digits10_v3通过搜索的方式进一步减少了除法操作。由于cpu并行处理技术,我们不能简单的用后面的clock cycle来衡量性能,但不难看出处理器对类型的还是非常敏感的,以整型和浮点的处理为例:
类型转换
- ints--> short/char (0~1 clock cycle)
- ints --> float/double (4~16个clock cycle), signed ints 快于 unsigned ints,唯一一个场景signed比unsigned快的
- short/char的计算通常使用32bit存储,只是返回的时候做了截取,故只在要考虑内存大小的时候才使用short/char,如array
- 注:隐式类型转换可能会溢出,有符号的溢出变成负数,无符号的溢出变成小的整数
运算
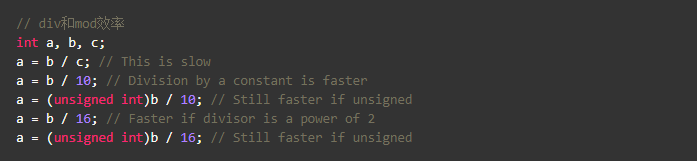
- 除法、取余运算unsigned ints 快于 signed ints
- 除以常量比除以变量效率高,因为可以在编译期做优化,尤其是常量可以表示成2^n时
- ++i和i++本身性能一样,但不同的语境效果不一样,如array[i++]比arry[++i]性能好;当依赖自增结果时,++i性能更好,如a=++b,a和b可复用同一个寄存器
代码示例
- 单精度、双精度的计算性能是一样的
- 常量的默认精度是双精度
- 不要混淆单精度、双精度,混合精度计算会带来额外的精度转换开销,如

- 浮点除法比乘法慢很多,故可以利用乘法来加快速度,如

这里介绍的大多是编译器的擅长但又不能直接优化的场景,也是平常优化中比较容易忽视的点,其实往往我们往前多走一步,编译器就可以工作得更好。
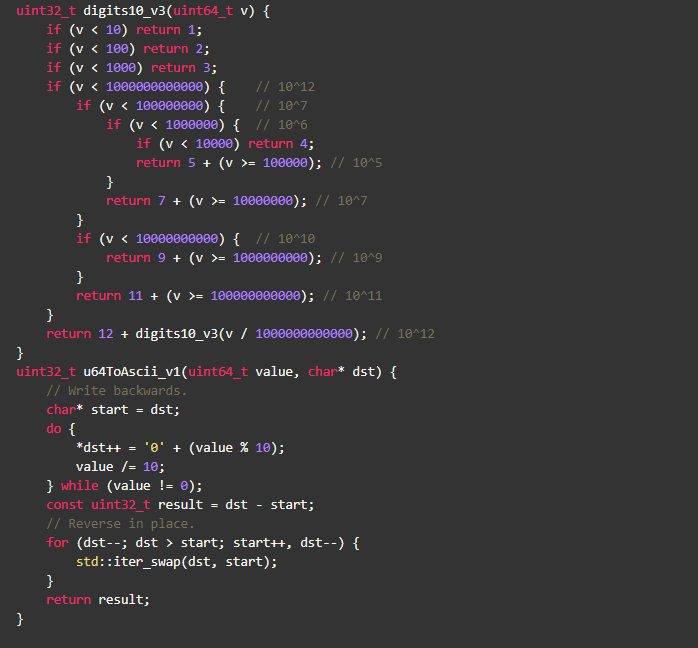
先看一个数字转字符串的例子,stringstream和sprintf 自然不会是我们考虑的对象,虽然protobuf库中的FastInt32ToBuffer很不错,其实还能优化,下面的版本就比例子中stringstream快6倍,代码如下:
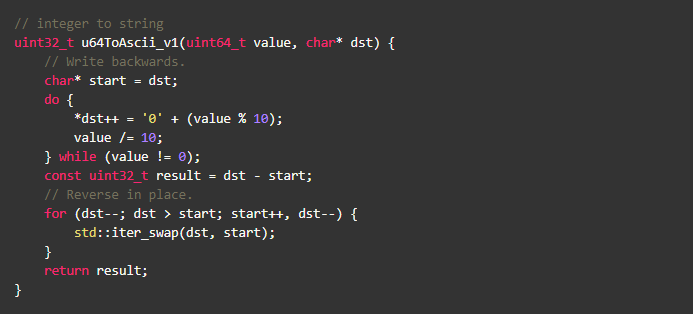
不用细读stringstream/sprintf的源码,反汇编看下就能知道个大概,对于转字符串这个场景,stringstream/sprintf就太重了,通常来说越少的指令性能也越好(如果你读过本系列的上一篇c++性能优化(一) ---- 从简单类型开始,不难发现,这句话也不正确,呵呵)。但本文讨论的重点是内存访问,就上面这段代码,有什么内存使用上的问题?如何进一步优化?
优化前还是得找一下性能热点,下面是vtune结果的截图(虽然cpu time和汇编指令的消耗对应得不是特别好):
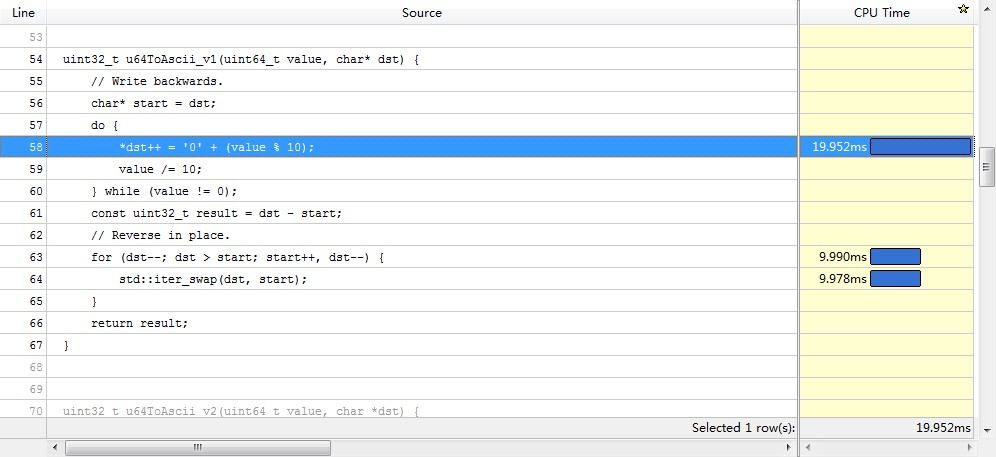
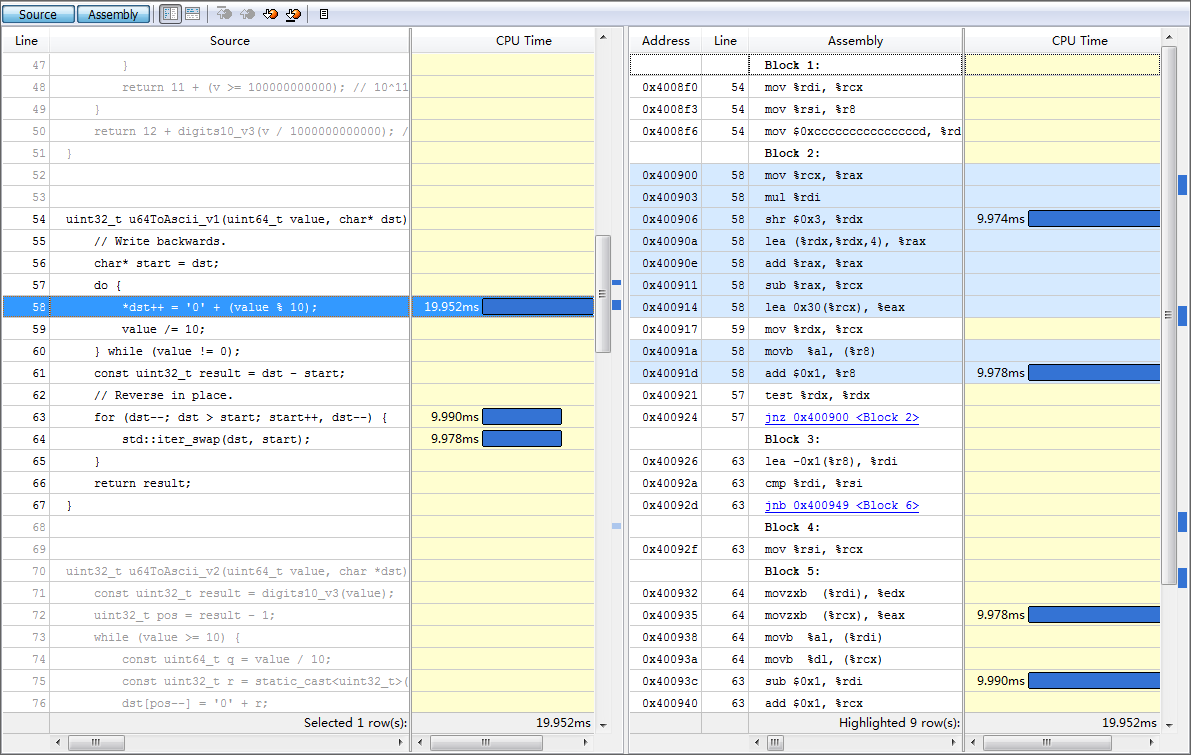
数组reverse的开销跟上面生成数组元素相近,reverse有这么耗时么?
从图中的汇编可以看出,一次swap对应着两次内存读(movzxb)、两次内存写(movb),因为一次写就意味着一个读和一个写,描述的是内存-->cache-->内存的过程。
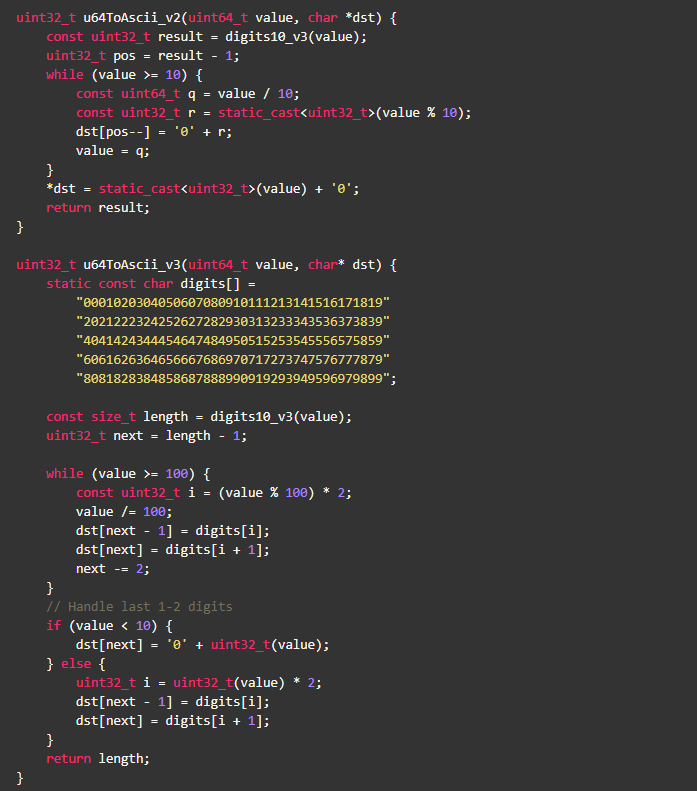
一个很自然的优化想法,应该尽量避免内存写操作,于是代码可以进一步优化,结合 Strength reduction,代码如下:
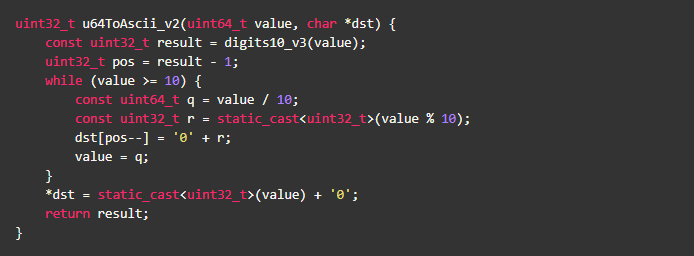
实测发现新版本比之前版本性能提升了10%,还有优化空间么?答案是,有。方案是:通过查表,一次处理2个数字,减少数据依赖,如:
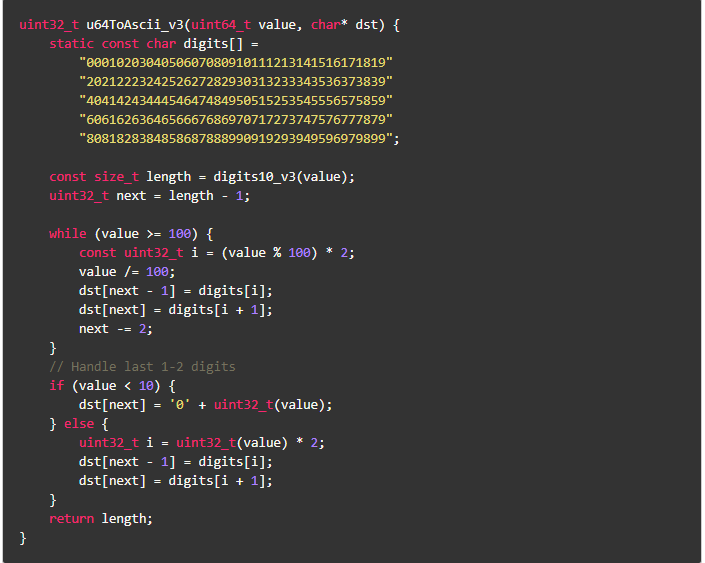
结论:
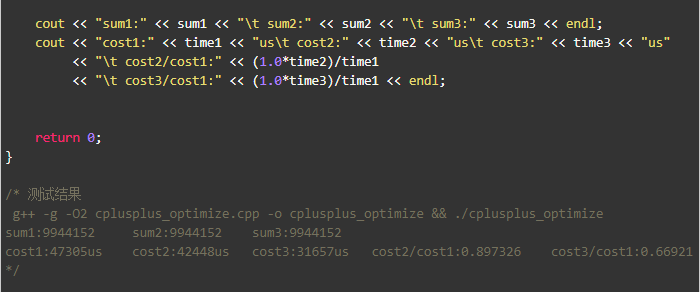
- u64ToAscii_v3性能比基准版本提升了30%;
- 如果用到悟时的那个测试场景,性能可以提升6.5倍。
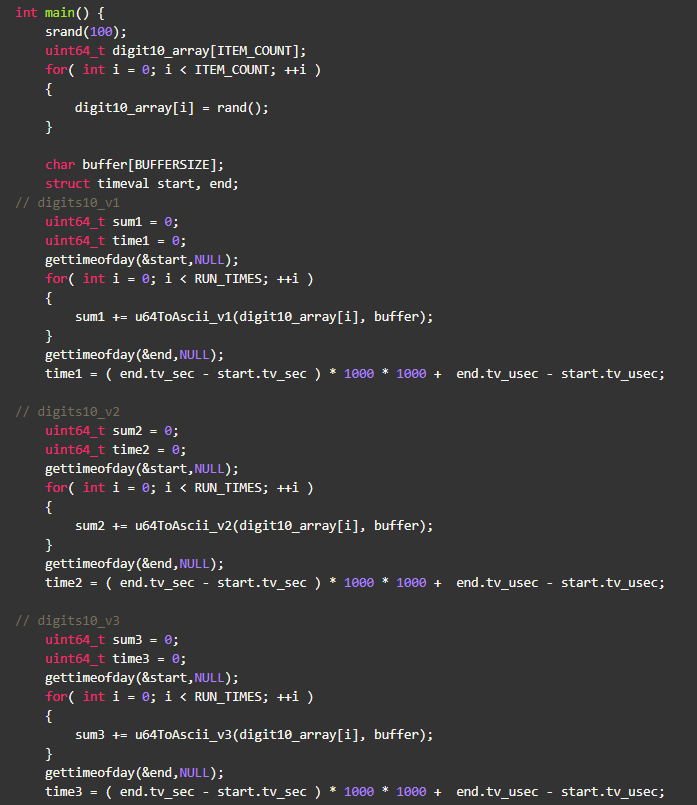
下面是完整的测试代码和结果:
看到优化写内存操作的威力了吧,让我们再看一个减少写操作的例子:

假定A、B、C都很小,且不会溢出,可以写成

如果需要考虑溢出,也可以改为

对于内存的写,最好的办法就是减少写的次数,那么内存的读取呢?
教科书的答案是:尽可能顺序访问内存。理解这句话还是得从cache line开始,因为实际的cpu比较复杂,下面的表述尝试做些简化,如有问题,欢迎指正:
cache line
- 假设L1cache大小为8K,cache line 64字节、4way,那么整个cache会分成32个集合,
81024/64=128=324,一个内存地址进入哪个cache line不是任意的,而是确定在某个集合中,可以通过公式(set )=(memory
address) / ( line size) % (number of sets )来计算,如地址是10000,则(set)=10000/64%32=28, 即编号为28的集合内的4个cache line之一。
- 用16进制来描述,10000=0x2710,一次内存读取是64bytes,那么访问内存地址10000即意味着地址0x2700~0x273F都进集合编号为28(0x1C)的cache line中了。
cache miss
可以看出,顺序的访问内存是能够比较高效而且不会因为cache冲突,导致药频繁读取内存。那什么的情况会导致cache miss呢?
- 当某个集合内的cache line都有数据时,且该集合内有新的数据就会导致老数据的换出,进而访问老数据就会出现cache miss。
- 以先后读取0x2710, 0x2F00, 0x3700, 0x3F00, 0x4700为例, 这几个地址都在28这个编号的集合内,当去读0x4700时,假定CPU都是以先进先出策略,那么0x2710就会被换出,这时候如果再访问0x2700~0x273F的数据就cache miss,需要重新访问内存了。
- 可以看出变量是否有cache 竞争,得看变量地址间的距离,distance=(number of sets ) (line size)=( total cache size) / ( number of ways) , 即距离为3264=8K/4=2K的内存访问都可能产生竞争。
- 上面这些不光对变量、对象有用,对代码cache也是如此。
对于内存的访问,可以考虑以下一些建议:
- 一起使用的函数存储在一起。函数的存储通常按照源码中的顺序来的,如果函数A,B,C是一起调用的,那尽量让ABC的声明也是这个顺序
- 一起使用的变量存储在一起。使用结构体、对象来定义变量,并通过局部变量方式来声明,都是一些较好的选择。例子见后文:
- 合理使用对齐(__attribute__((aligned(64)))、预取(prefecting data),让一个cacheline能获取到更多有效的数据
- 动态内存分配、STL容器、string都是一些常容易cache不友好的场景,核心代码处尽量不用
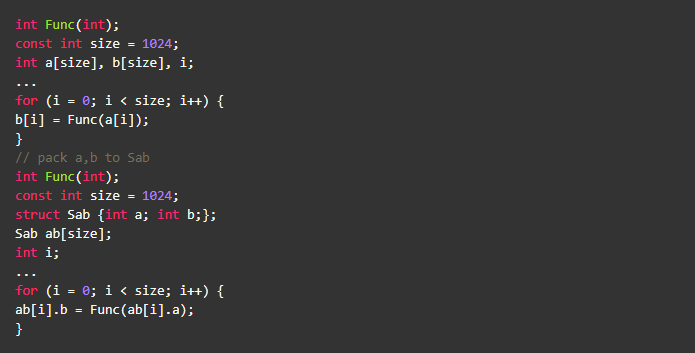
让我们再回到最前面的优化,u64ToAscii_v3引入了局部静态变量(digits),是否合适?通常来说,要具体问题具体分析,没有标准答案。
静态变量和栈地址是分开的,可能会带来cache miss的问题,通过去掉static修饰符,直接在栈上声明变的方式可以避免,但这种做法可行有几个前提条件:
- 变量大小是要限制的,不超出cache的大小(最好是L1 cache)
- 变量的初始化在栈上完成,故最好不要在循环内部定义,以避免不必要的初始化。
其实内存访问和CPU运算是没有一定的赢家,真正做优化时,需要结合具体的场景,仔细测量才能得到答案。
前面两个实例分别从编译器和内存使用的角度介绍了一些性能优化的方法,后面内容则会回到cpu,从指令并行的角度看看我们常见的逻辑控制有哪些可以优化的点。

通常一个CPU可以并行执行多条指令,如:4条浮点乘法,等待4个内存访问、一个还为到来的分支比较,不同的运算单元也是可以并行计算,如for(int i=0; i < N; ++i) a[i]=i0.2; 这里的i < N和++i 在i0.2可以同时执行。提升指令并行能力,往往就能达到提升性能的目的。
从流水线的角度看,指令pipeline的几个阶段:fetch、decode、execute、memory-access、write-back,除了存储器的访问效率会影响并行度外,下一条指令的fetch/decode也很关键,而跳转和分支则是又一个拦路虎,这也是本文接下去要主要分析的地方: - 函数调用使得处理器跳到另外一个代码地址并回来,一般需要4 clock cycles,大多数情况处理器会把函数调用、返回和其他指令一起执行以节约时间。
- 函数参数存储在栈上需要额外的时间( 包括栈帧的建立、saving and restoring registers、可能还有异常信息)。在64bit linux上,前6个整型参数(包括指针、引用)、前8个浮点参数会放到寄存器中;64bit windows上不管整型、浮点,会放置4个参数。
- 在内存中过于分散的代码可能会导致较差的code cache
- 避免不必要的函数,特别在最底层的循环,应该尽量让代码在一个函数内。看起来与良好的编码习惯冲突(一个函数最好不要超过80行),其实不然,跟这个系列其他优化一样,我们应该知道何时去使用这些优化,而不是一上来就让代码不可读。
- 尝试使用inline函数,让函数调用的地方直接用函数体替换。inline对编译器来说是个建议,而且不是inline了性能就好,一般当函数比较小或者只有一个地方调用的时候,inline效果会比较好
- 在函数内部使用循环(e.g., change for(i=0;i<100;i++) DoSomething(); into DoSomething()
{ for(i=0;i<100;i++){ ... }}) - 减少函数的间接调用,如偏向静态链接而不是动态链接,尽量少用或者不用多继承、虚拟继承
- 优先使用迭代而不是递归
- 使用函数来替换define,从而避免多次求值。宏的其他缺点:不能overload和限制作用域(undef除外)

常见的分支预测场景有if/else,for/while,switch,预测正确0~2 clock cycles,错误恢复12~25 clock cycles。
一般应用分支预测的正确率在90%以上,但个位数的误判率对有较多分支的程序来说影响还是非常大的。分支预测的技术(或者说策略)非常多,这里不会展开介绍,对写程序来说,我们知道越简单的场景越容易预测正确:如分支都在在一个循环内或者几乎没有其他分支。
如果对分支预测的概念和作用还不清楚的话,可以看看后面的参考文档。几个影响分支预测因素:
branch target buffer (BTB)

Return Address Stack (RAS)

消除条件分支
- 代码实例

- 优化版本1

- 优化版本2

- 优化版本3

bool类型变换
- 实例代码

- 编译器的行为是
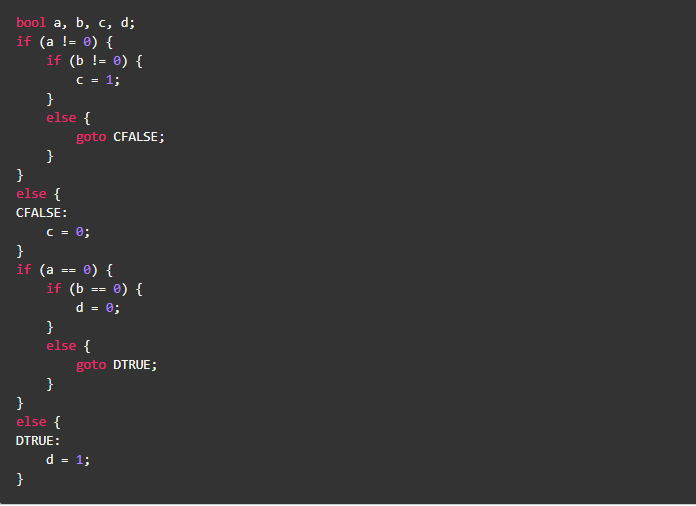
- 优化版本

- 实例代码2

- 反例
a && b 何时不能转换成a & b,当a不可能为false的情况下
a | | b 何时不能转换成a | b,当a不可能为true的情况下
循环展开
- 实例代码

- 优化版本

- 优化说明
- 优点:减少比较次数、某些CPU上重复次数越少预测越准、去掉了if判断
- 缺点:需要更多的code cache or micro-op cache、有些处理器(core 2)对于小循环性能很好(小于65bytes code)、循环的次数和展开的个数不匹配
- 一般编译器会自动展开循环,程序员不需要主动去做,除非有一些明显优点,比如减少上面的if判断
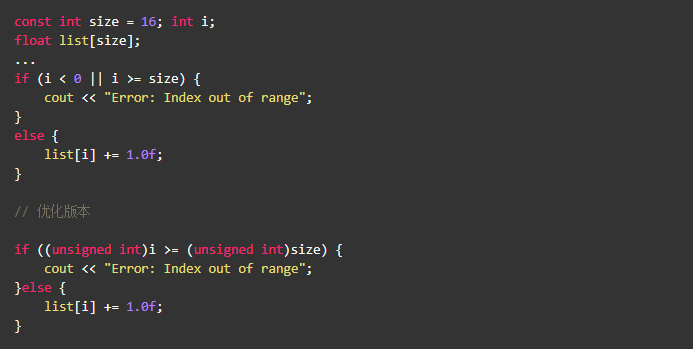
边界检查
- 实例代码1
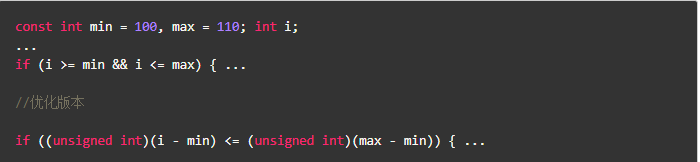
- 实例代码2
使用数组
- 实例代码1
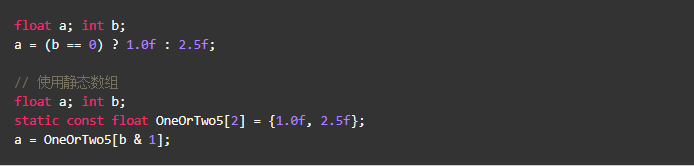
- 实例代码2

整形的bit array语义,适用于enum、const、define
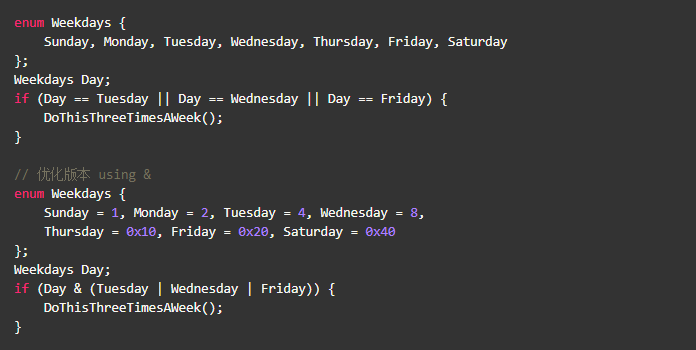
- 尽可能的减少跳转和分支
- 优先使用迭代而不是递归
- 对于长的if...else,使用switch case,以减少后面条件的判断,把最容易出现的条件放在最前面
- 为小函数使用inline,减少函数调用开销
- 在函数内使用循环
- 在跳转之间的代码尽量减少数据依赖
- 尝试展开循环
- 尝试通过计算来消除分支
<<深入理解计算机系统>>
http://en.wikipedia.org/wiki/Instruction_pipelining
http://web.cecs.pdx.edu/~alaa/ece587/notes/bpred-6up.pdf
http://cseweb.ucsd.edu/~j2lau/cs141/week8.html
http://en.wikipedia.org/wiki/Branch_predictor
http://en.wikipedia.org/wiki/Branch_target_predictor
http://www-ee.eng.hawaii.edu/~tep/EE461/Notes/ILP/buffer.html
http://book.51cto.com/art/200804/70903.htm
http://en.wikipedia.org/wiki/Strength_reduction
https://www.facebook.com/notes/facebook-engineering/three-optimization-tips-for-c/10151361643253920
http://people.cs.clemson.edu/~dhouse/courses/405/papers/optimize.pdf
http://www.agner.org/optimize/optimizing_cpp.pdf
更多技术干货敬请关注云栖社区知乎机构号:阿里云云栖社区 - 知乎
8A新闻
联系我们
公司名称: 8A-8A娱乐-注册登录商务站
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

