行业新闻
训练神经网络--优化方法及其优化器
目录
在训练神经网络的时候,有归一化,正则化等优化模型性能的方法,但是在做这些优化之前,我们需要确定一种优化方法或者说是优化器,优化方法会对模型的 性能有不少的影响,pytorch里面自带了不少优化器,可以自动的更新梯度,loss等参数,是比较方便的。
对比批量梯度下降法,假设从一批训练样本n中随机选取一个样本![]() ,模型参数为
,模型参数为![]()
,?代价函数为![]() ,梯度为
,梯度为![]() ,学习率为
,学习率为![]() ,则使用随机梯度下降法更新参数表达式为:
,则使用随机梯度下降法更新参数表达式为:
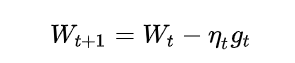
?其中,![]() ,表示随机选择的一个梯度方向?
,表示随机选择的一个梯度方向?![]() 表示t时刻的模型参数,我们在这里面会加入随机噪声,虽然不是严格按照当前梯度下降的 ,但是会大概的往正确方向移动。
表示t时刻的模型参数,我们在这里面会加入随机噪声,虽然不是严格按照当前梯度下降的 ,但是会大概的往正确方向移动。
?在等高线上,损失值对于水平变化很不敏感,但是对于垂直变化却很敏感,随机梯度下降算法,就像如下图的红线,虽然最终会走到终点,但是会很慢,效率不高。

另外一个问题就是如下,当SGD算法遇到类似的情况,陷入局部最小值,不停的在局部最小值移动,其实可能另外的地方有更好的结果。

这是在SGD的基础上进行优化的算法,SGD是随机下降算法,每次会大概沿着正确的方向走,效率是比较低的,但是我们可以引入一个参数动量Momentum,用来积攒历史梯度信息动量来加速SGD,

通俗的来说就是用上一次梯度的方向以及当前梯度的方向来共同决定,当前梯度下降的方向,当然他们会有权重,方向会像权重大梯度的方向偏移。
动量主要解决SGD的两个问题:一是随机梯度的方法(引入的噪声);二是Hessian矩阵病态问题(可以理解为SGD在收敛过程中和正确梯度相比来回摆动比较大的问题)。
主要思想就是在训练的时候保存一个梯度平方和的持续估计,一直累加梯度平方,当我们更新参数向量时,用这个参数向量除以当前累加的值。源代码实现如下
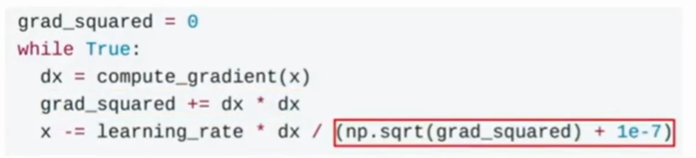
??由于梯度平方和一直增加,会导致梯度移动步长会一直减小,在凸函数问题中,表现很好,主要是凸函数最低端变化步长越小越容易接近最优值

?对比两种算法代码实现,RMSProp算法就是在AdaGrad基础上加了一个梯度平方和的递减率,防止梯度一直递增,这种就像动量梯度下降一样,都是消除梯度下降过程中的摆动来加速梯度下降的方法。梯度更新公式:

更新权重的时候,使用除根号的方法,可以使较大的梯度大幅度变小,而较小的梯度小幅度变小,这样就可以使较大梯度方向上的波动小下来,那么整个梯度下降的过程中摆动就会比较小,就能设置较大的learning-rate,使得学习步子变大,达到加快学习的目的。

Adam算法则是将前面的算法结合起来,是目前最优的算法之一
?Adam包括偏置修正,修正从原点初始化的一阶矩(动量项)和(非中心的)二阶矩估计。Adam算法策略可以表示为:

其中,和分别为一阶动量项和二阶动量项。为动力值大小通常分别取0.9和0.999;,分别为各自的修正值。表示t时刻即第t迭代模型的参数,表示t次迭代代价函数关于W的梯度大小;?是一个取值很小的数(一般为1e-8)为了避免分母为0。
比较一下一上算法

?从上图来看Adam理论上来说最好,但是在实际情况它可能没有RMSProp算法高效
8A新闻
联系我们
公司名称: 8A-8A娱乐-注册登录商务站
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

