公司新闻
AI换脸实战教学(FaceSwap的使用)---------第一步Extration:提取人脸。
市面上有多款AI换脸的方法,笔者这里节选了Github那年很火的开源项目FaceSwap:
(很早就实践了,但是忘记记录啦hhh,请勿用于不正当用途哦)
做了一篇详细教学,包括配置,参数设置,换脸效果经验之谈。感兴趣的学友可以留言一起交流。
先上成果展示下吧(垃圾显卡跑了2天,有条件好的显卡跑个1周估计效果会好一些):
左边是替换后的效果,别告我侵权,求你了。。没有商业用途。。


ok,为了实现换脸,我们先从安装到配置工具开始(配置好的请直接跳到第一步),以下请按步骤操作:
首先需要下载该项目,这里建议直接下载GUI版软件:https://faceswap.dev/download/
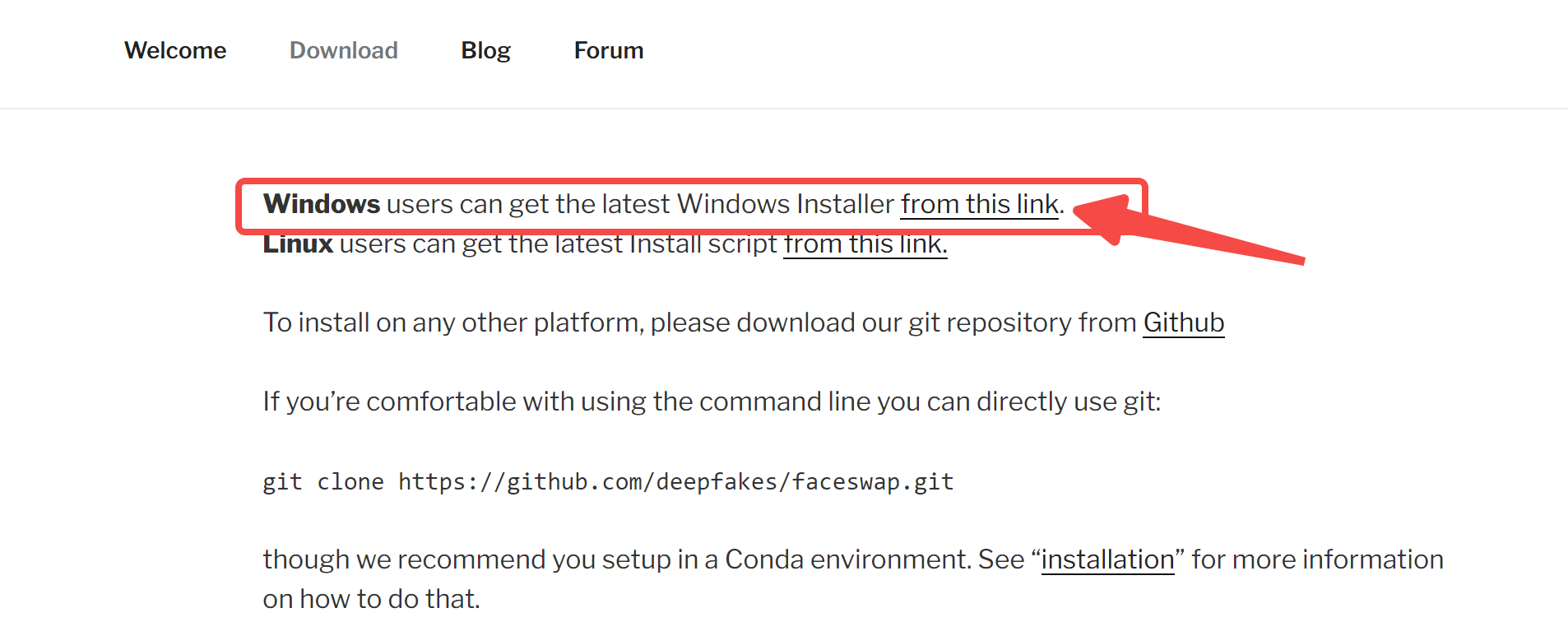
然后是安装:
第一页选择安装地址,根据自己喜好。
第二页需要选择GPU或者CPU版。 有支持的GPU进行训练当然是最好的,如果没有的话只能CPU了(提取,训练过程很慢)
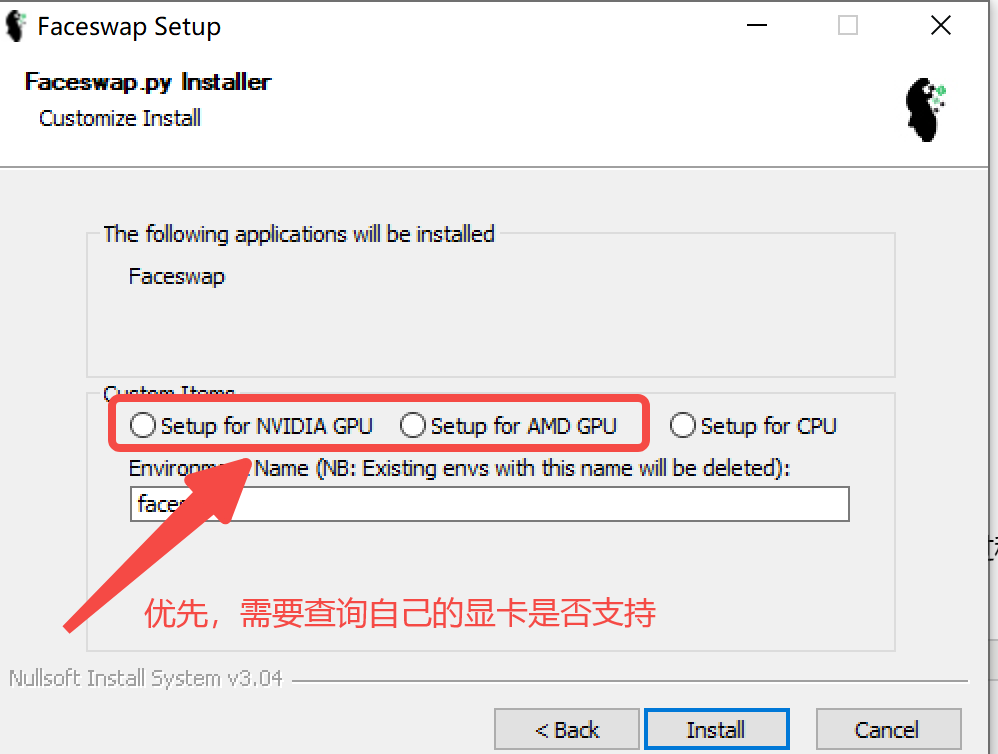
{ PS: 如何查询是否支持呢,
GPU版需要保证三个包是匹配的:
tensorflow-GPU, cuda,cudnn
首先,更新显卡驱动:https://www.nvidia.com/Download/index.aspx?lang=en-us
其次,下载与GPU匹配的cuda:https://developer.nvidia.com/cuda-downloads?target_os=Windows&target_arch=x86_64
最后,下载与GPU匹配的cudnn: https://developer.nvidia.com/zh-cn/cudnn
最最后下载tensorflow-GPU
}
安装好以后启动,界面如下:
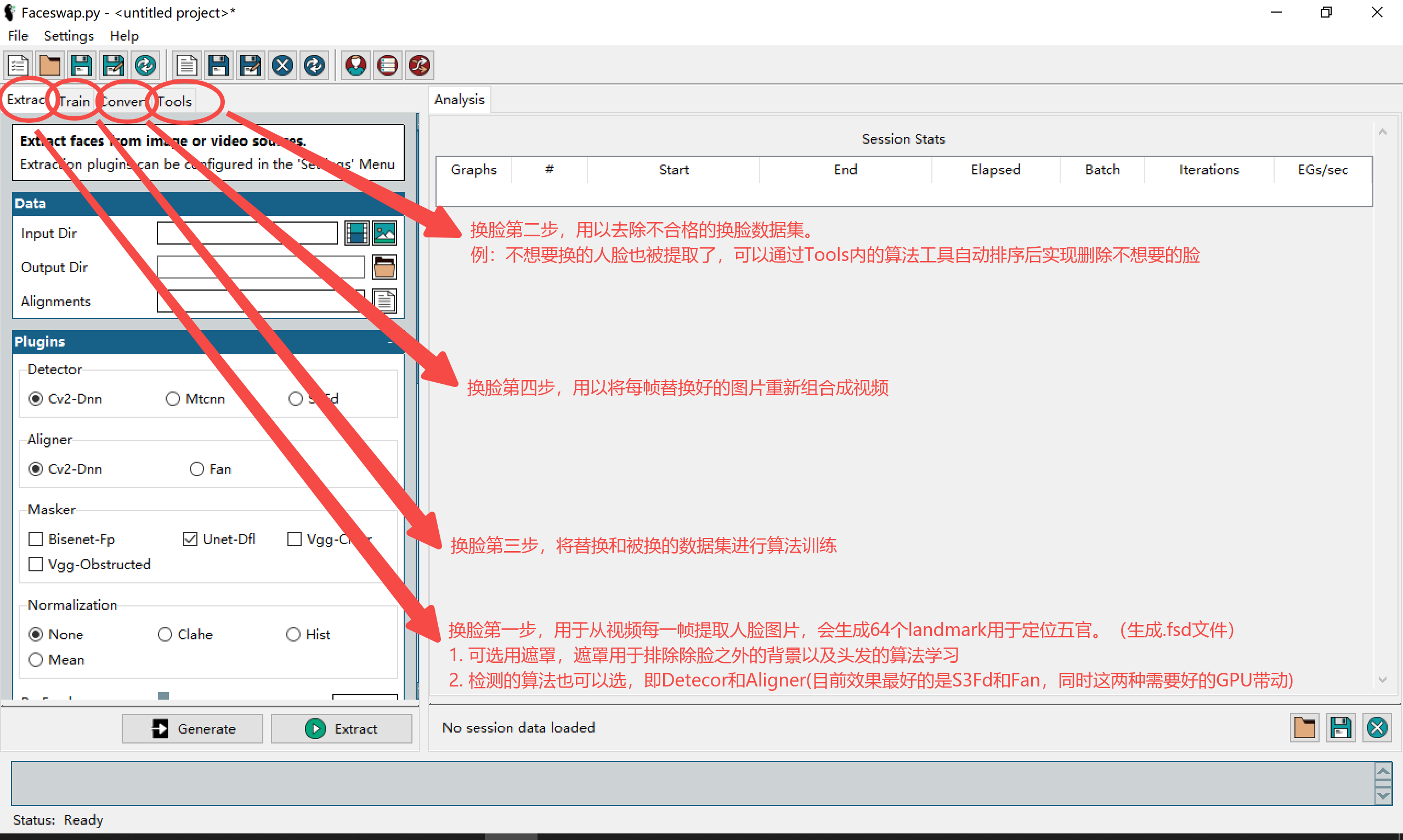
(landmark是68个点,提取生成的带landmark和遮罩的文件格式是fsa,不是fsd,懒得重写了,hh)
第一步:
好的,我们开始第一步, extract的目的是:从视频中的每一帧提取人脸,生成图片集和一个fsa文件(带landmark和mask的数据集),用于模型训练的输入。
什么是landmark?如下图,是指算法识别出的每张图片人脸边界的68个点。

什么是mask?如下图,是指算法识别出的每张脸的脸区,摒弃遮挡/背景/头发等信息。

简单来说,提取包括三个阶段:检测、对齐和遮罩生成:
- 检测- 在框架内查找人脸的过程。检测器扫描图像并选择图像中它认为是人脸的区域。
- 对齐- 找到面部内的“landmark”并一致地定向面部。这会将候选者从检测器中取出,并尝试找出潜在面部的关键特征(眼睛、鼻子等)在哪里。然后它会尝试使用此信息来对齐面部。
- 遮罩生成- 识别包含面部的对齐面部部分,并屏蔽那些包含背景/障碍物的区域。
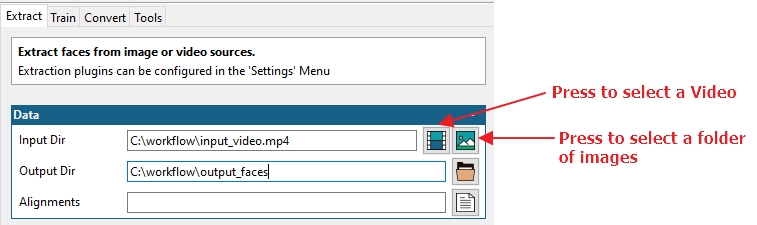
-
Input Dir:首先我们需要一个源文件。此处设置为视频文件(视频图标)或包含一系列图像的文件夹(图片图标)。
-
Output Dir:接下来我们需要告诉进程将提取的人脸图片集保存到哪里。单击旁边的文件夹图标以选择输出位置
-
Alignments:此选项用于为对齐文件指定不同的名称/位置。建议留空,则生成的fsa文件会保存到默认位置,与源视频名字相同(与源视频/源图位于同一位置)
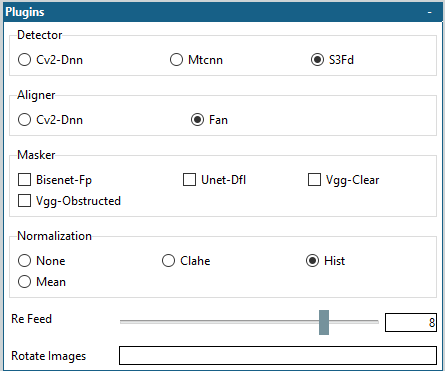
plugins模块用于首先检测图像中的人脸、读取人脸标志以对齐图像并使用各种遮罩方法创建遮罩。
-
Detector, Aligner:检测和对齐的算法,推荐使用S3FD作为检测算法, FAN作为对齐算法 。(二者效果好,对显卡要求高)
-
Masker:遮罩的算法。除了基于人脸landmark的遮罩之外,此处是另一种针对人脸区域的特殊遮罩(可不选,也可多选,好的遮罩算法有助于过滤掉遮挡物)。遮罩都使用 GPU,因此添加的遮罩越多,提取速度就越慢。
每个面具/遮罩都有不同的优点和缺点。(后面训练和转换的过程中若是基于神经网络的遮罩进行训练或转换源文件时,建议此处选一个遮罩算法)
ps: 遮罩此处可不选,在步骤二中对fsa数据集优化后,在Tools里同样可以补充再搞这个步骤。
遮罩算法对比:
- BiSeNet-FP,从面具中排除头发和耳朵(默认设置):

- BiSeNet-FP,面罩中包含头发和耳朵的(全头训练所需的头发),可在界面上方的setting中找到对应的遮罩设置:
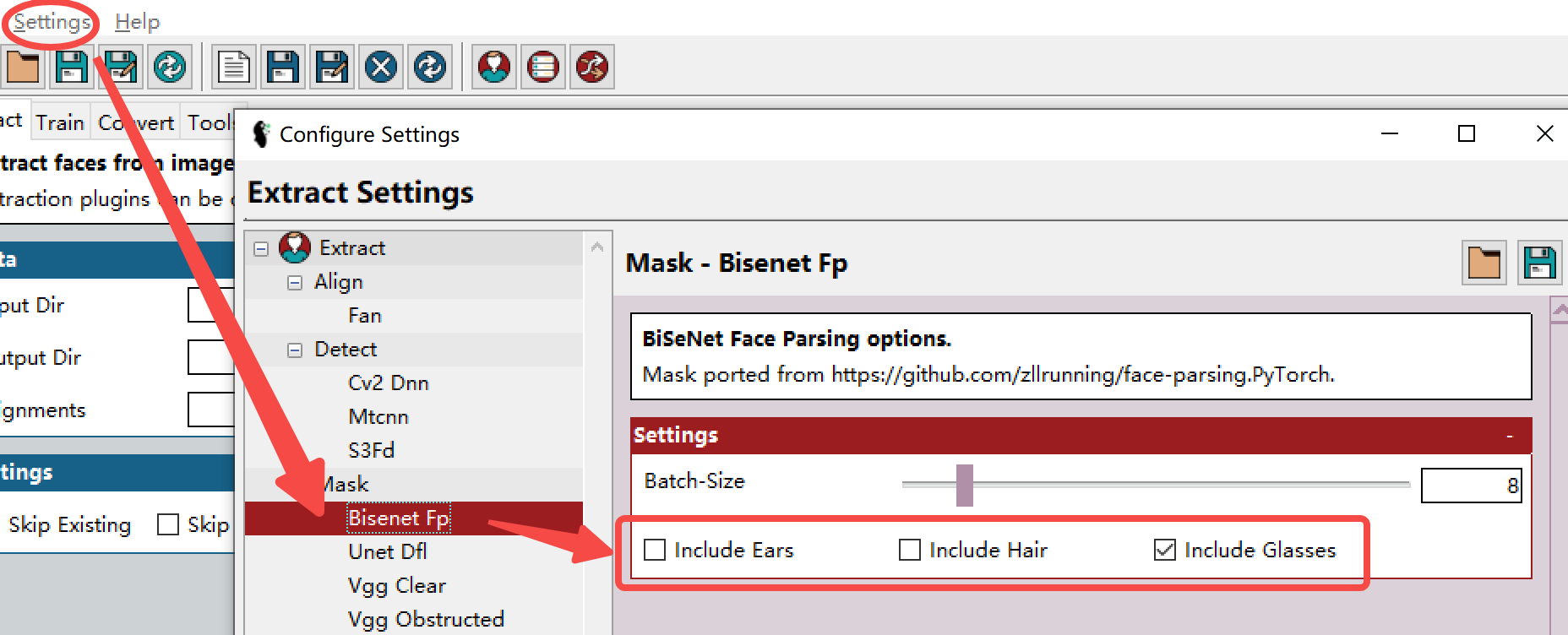

- Unet-DFL - 一种神经网络掩码,旨在提供大部分正面的智能分割。面具模型已经过社区成员的培训。

- VGG-Clear - 一种神经网络掩码,旨在对大部分正面没有障碍物的人脸进行智能分

- VGG-Obstructed - 旨在提供大部分正面的智能分割。面具模型经过专门训练,可以识别一些面部障碍物(手和眼镜)。

- landmark 68个点遮罩(不选也会有,真正的默认遮罩,有时候因为脸的不全原因,所以还是要加上上面的某1个或几种遮罩):

-
PS: 默认landmark遮罩的其中一个主要大问题是这个算法仅会囊括检测的脸眉毛上方,有可能会造成最终换脸两重眉毛的效果,这也是以上这些自选算法遮罩的目的,能够让识别到眉毛上方的地方,避免这个问题。
Normalization, 顾名思义,数据集的归一化:归一化可以在光照不理想的情况下更好地找到人脸。不同的归一化方法适用于不同的数据集,实测的话推荐“hist”归一化。选正则选项的话会稍微减慢提取速度,但对齐效果更好。
Re Feed:此选项会将稍微调整过的检测到的人脸重新送回对准器,然后平均最终结果。这有助于减少“微抖动”。 如果是用于训练数据集,即第三步Training用,设置其为0,如果是为了转换,设在0-8,反复提取可以实现精益求精用,但是会慢很多),效果也截一个。
下图显示了 re-feed 设置为 8(左)与 re-feed 设置为 0:

Rotate Images:针对 CV2-DNN !,可能会无法识别旋转后的人脸。其他对齐算法选这个会降低速度,毫无收益。
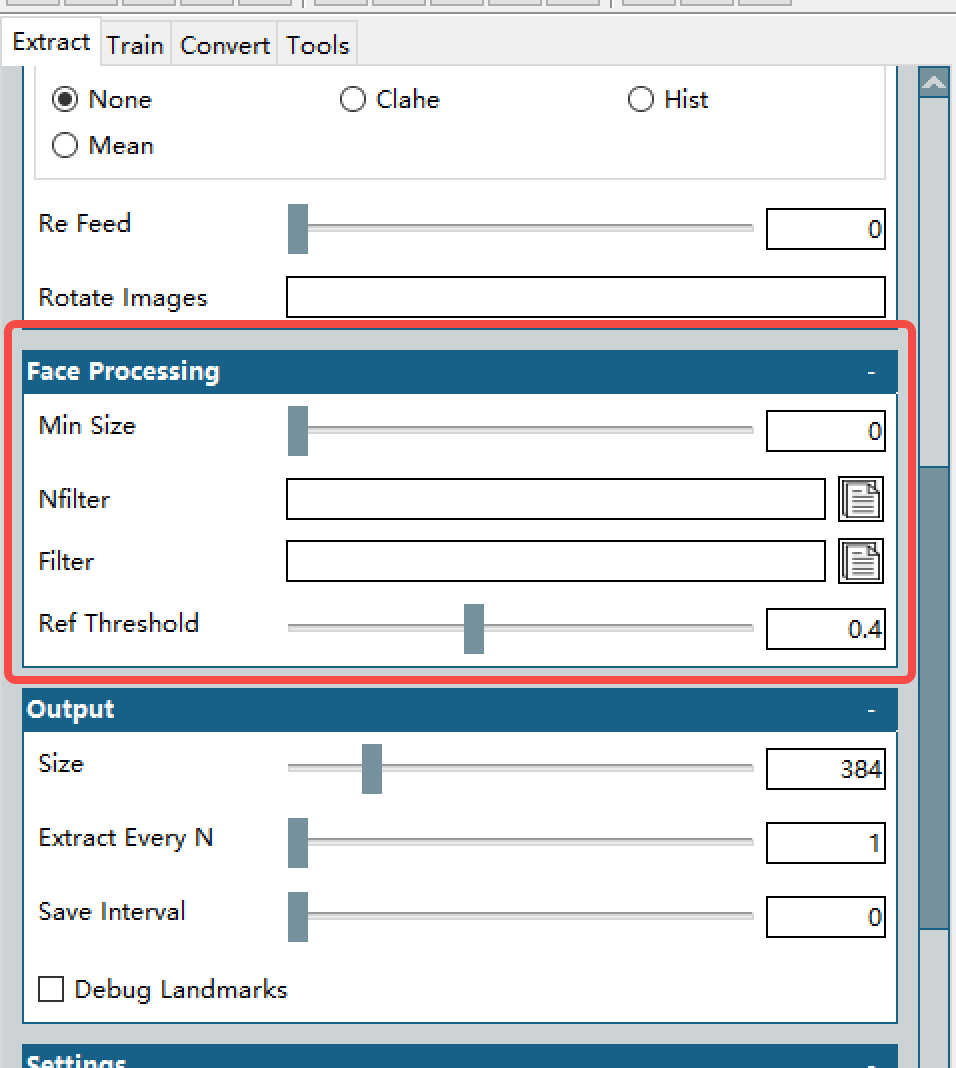
Min Size:设置一个高于零但比较低的值,用以过滤掉明显太小而不能成为脸的东西。(取决于源视频中人脸的大小,比如都很小,那这个值确保比源视频中的常见脸的尺寸要低,比如一个电影片段,镜头里除了需要提取的主人公的脸,旁边还放有一本书上,书有人脸,这个值就是卡掉书上的这个大小的人脸,确保不算在内)
Filter/nFilter, Ref Threshold:这俩选项用于过滤掉不需要的脸。什么意思呢,就是针对性的要谁的脸(Filter选一张照片),或者针对性的不要谁(Nfilter上传N张你不想要检测到人脸的照片,记住是每个照片必须只有一个人脸,可以传多张,用以屏蔽多个人)。Ref Threshold用于取决于判断的严格度,就是拉到1的话就很松,越低就越严,相当于你想要的监考老师的分数,严的就很难受,分数就低。
PS: Filter/nFilter, Ref Threshold这部分可以不上传图,靠第二步的tools相关功能去筛选不想要的脸,根据官方FAQ的说法,用TOOLS在第二步中处理效率更高,因为如果使用了这个过滤器明显的会降低提取速率。
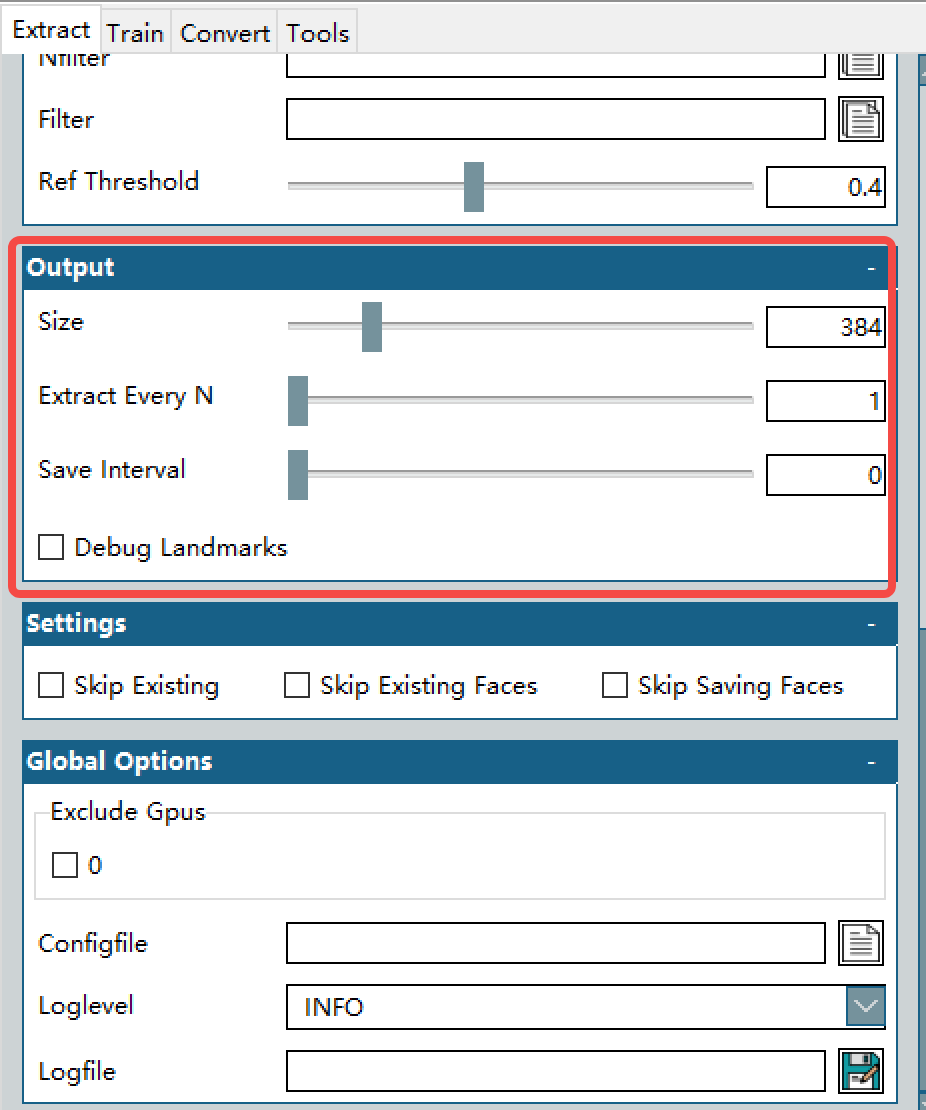
Size: 提取图像的大小,通常 512px 对于大多数模型来说都可以(全头提取图像的大小),这个就是神经网络的输入图片像素,不同算法可能仅支持固定格式的输入图片大小。比如对于“面部”居中,模型可用的图像大小将为 384 像素。使用“传统”居中进行训练时,可用的图像大小为 308 像素。
Extract Every N: 这个选项意思是,多少帧提取一个脸,我举个例子,一般的25fps的视频,有可能25帧每一帧的变化很小,那么就是提取了一堆相似的废物数据集,实际上每12-25提取一次就行(大约是半秒到1秒,也就是你换个表情和表情变化怎么也得半秒,不信的话你自己试试。。。)
Save Interval: 保存间隔,随缘吧,多少帧保存一次。默认就行,默认就是全搞完了一次性存下来。
Debug Landmarks: 在提取的脸上调整landmarks(做事真就这么细?,正常不勾选)
Settings: 不解释了,跳过已有的(指当前fsa文件中),跳过已有的脸(指当前fsa文件中),跳过已保存过的脸
Exclude Gpus: 哪个CPU你不想在跑的时候使用, 你如果全勾选了(说明你不想用任何GPU),会变成CPU模式
Configfile:载入一个配置(就是刚刚设置的这些玩意可以保存,下次直接载入就行)
Loglevel: 日志类型,默认就行。选debug会有报告(你愿意看的话),选TRACE会有一大堆数据生成
Logfile:log存放地址路径,留空默认生成在faceswap的目录下。
以上选好的话,
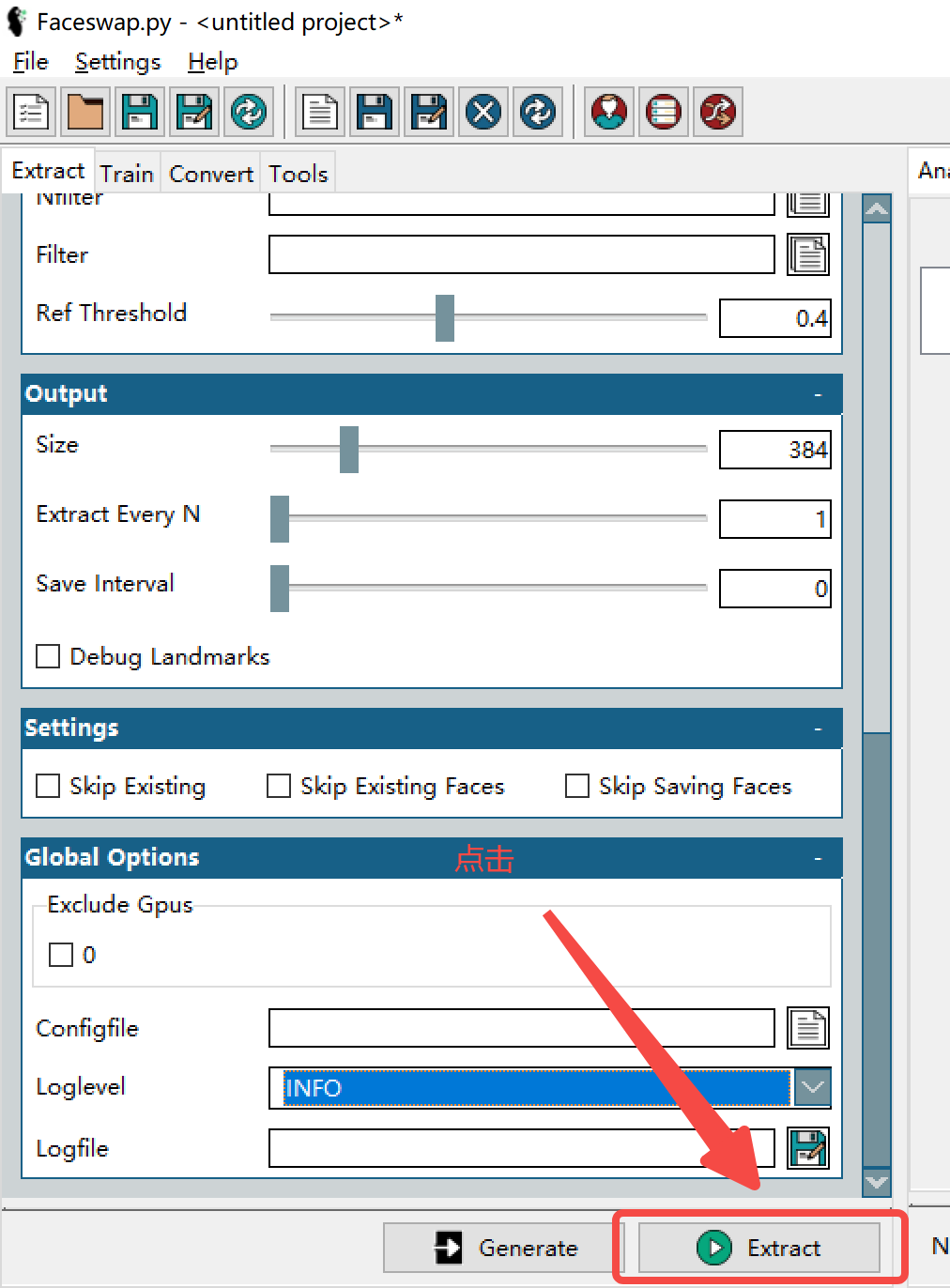
第一步,完成。
下一章教大家如何利用tools模块里的各种工具。
{
Alignments:排序,删脸,提取,重命名
Effmpeg: 视频组装合成
Restore:恢复训练的模型
Mask: 添加遮罩
Sort:排序
Preview:交换效果预览
)
第二章Tools部分月内更新吧,反正也是自己看的。。
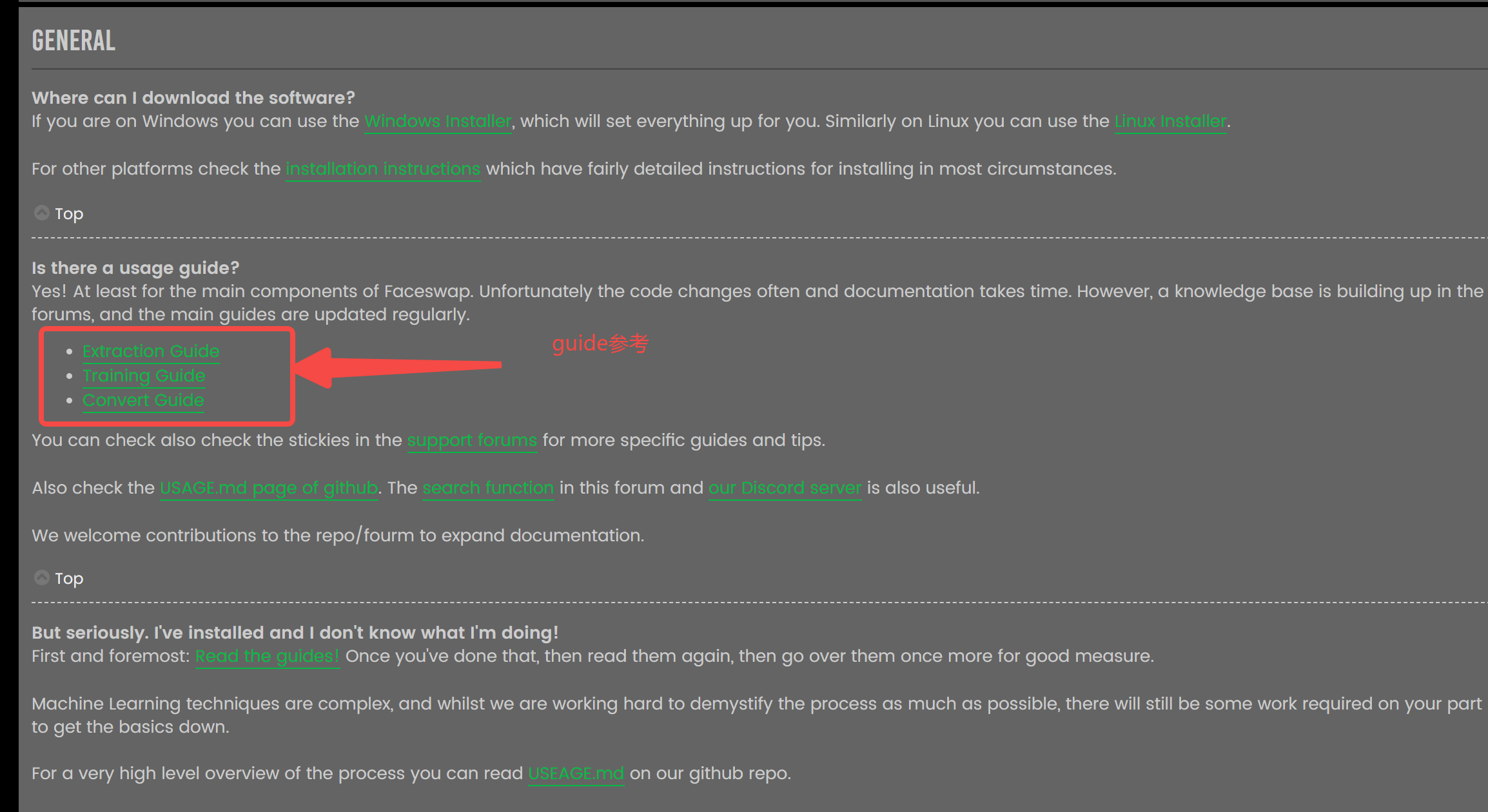
最后,操作流程的任何问题都可以在官方FAQ中找到,贴个地址,真有问题,去社区发帖问或者留言探讨~
https://forum.faceswap.dev/app.php/faqpage
8A新闻
联系我们
公司名称: 8A-8A娱乐-注册登录商务站
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

