行业新闻
#深入探究# Adam和SGDM优化器的对比
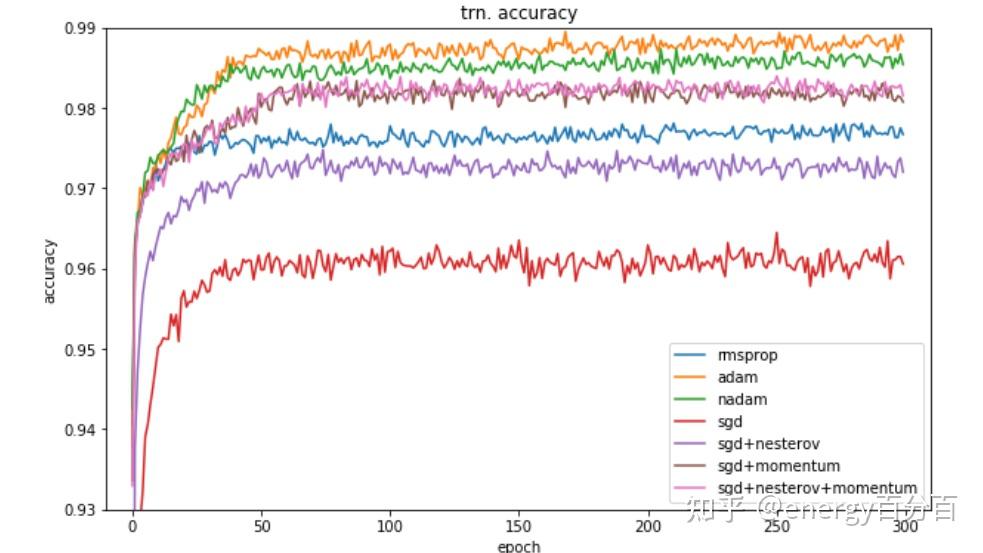
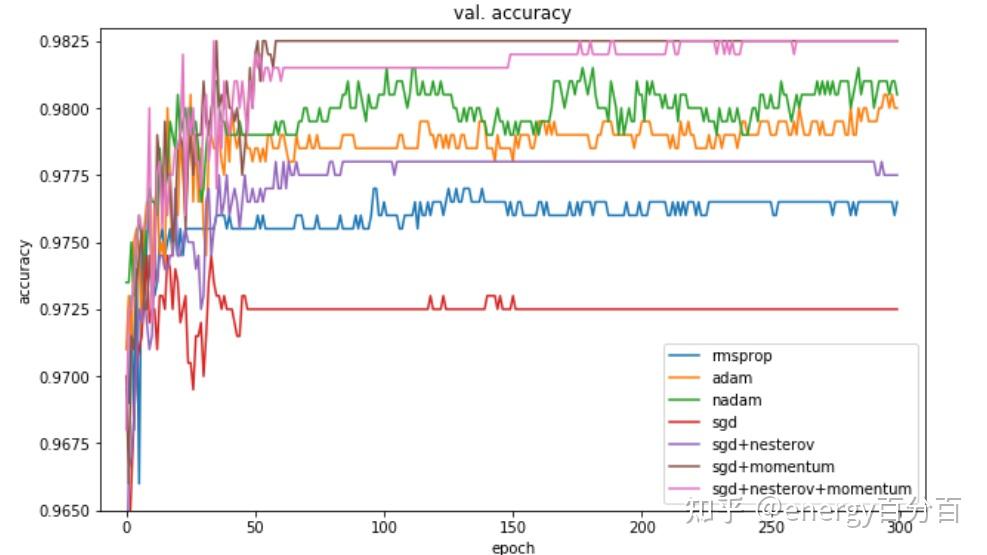
energy百分百:深度解析Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam等优化器energy百分百:通俗理解 Adam 优化器Adam和SGDM作为当今最优秀的两种深度学习优化器,分别在效率和精度上有着各自的优势,下面我们将分析两种优化器各自优势的原因,两边的两张图分别是 几种常见的优化器在猫狗分类数据集上的分类准确率曲线,第一个是训练集,第二个是测试集
以下两张图是某个NLP任务中,几种模型的准确率和困惑度指标变换曲线
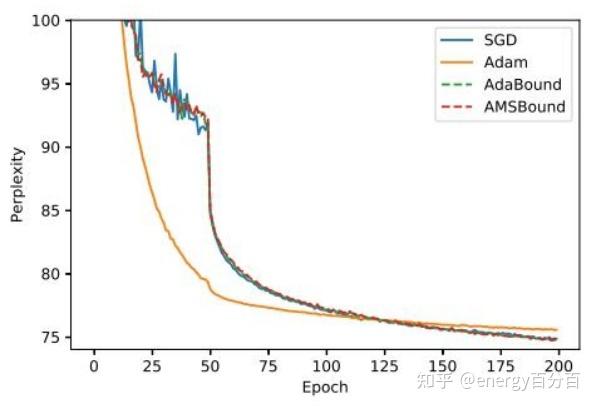
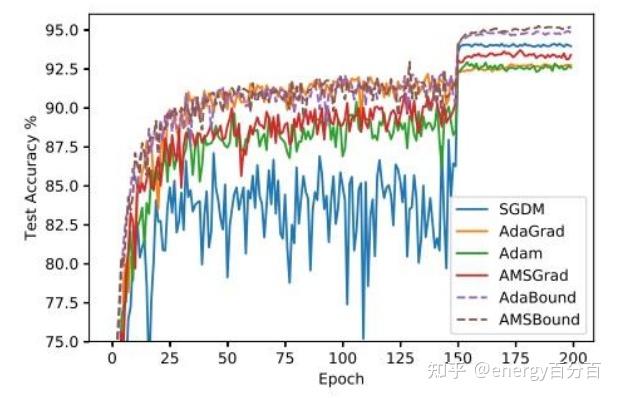
通过上边两幅图片可知:
- Adam在训练集上的准确率较高,SGDM在测试集上的准确率较高
- Adam的速度更快,但SGDM能够得到好的效果
第一个结论可以用下边这个图来解释:
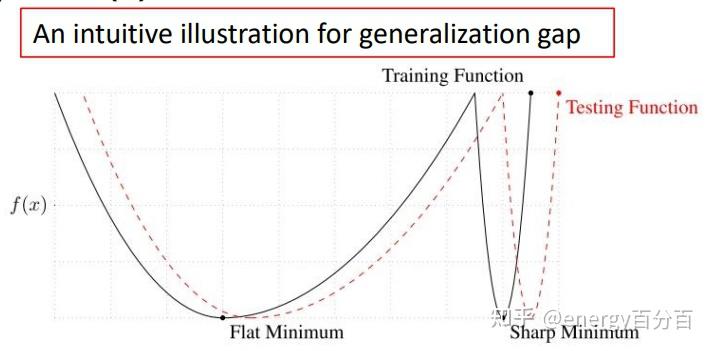
虽然测试集和训练集都来自同一数据集,但是测试集和训练集在数据分布上还是有着些许偏差(或者说参数的最优值存在细微偏差);同一个损失函数可能包含多个最优解,而这些最优解又可以分为 Flat Minimum 和 Sharp Minimum,其中测试集和训练集上 Flat Minimum 重合的几率较大,Sharp Minimum 重合的几率较小(如上图所示);因此在训练集上得到的是 Flat Minimum,那么在测试集也能得到 Minimum 值得概率会很大,我们要尽可能的得到 Flat Minimum
Adam 得到最优解多数时候是 Sharp Minimum,而 SGDM得到往往是Flat Minimum,这也就解释了为什么SGDM在测试集上能够得到更好的效果
至于第二个结论,原因是 Adam 在 SGDM的基础上增加了自适应学习率机制,能够使Adam针对不同的参数分配不同的学习率,从而增加优化速度
通过上述分析我们得知,Adam在前期优化速度较快,SGDM在后期优化精度较高;SWATS算法在提出在前期使用Adam算法,后期使用SGDM算法,从而在保证算法精度的同时,提高了算法的速度,但此算法存在两个问题:何时切换和如何切换两种算法,因为原作者并并没有针对这两个问题给出确切的解决方案,因此SWATS算法的应用并不是很广泛
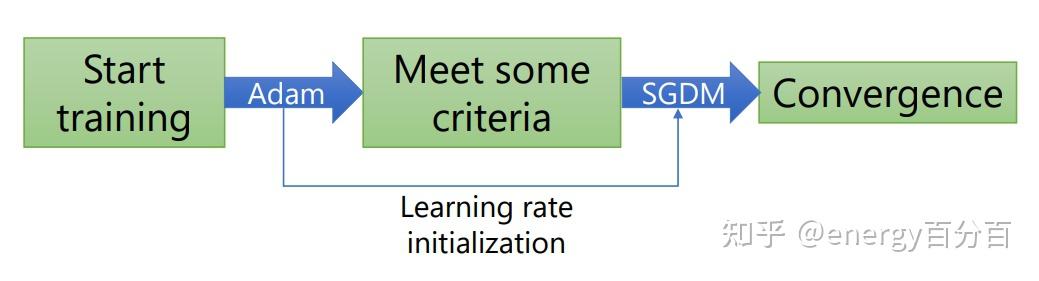
首先我们看一下Adam 在使用 warm-up前后的区别。
下图横轴代表模型中参数中梯度的绝对值大小,纵轴代表迭代次数,高度代表当前迭代次数下当前梯度大小的参数数量
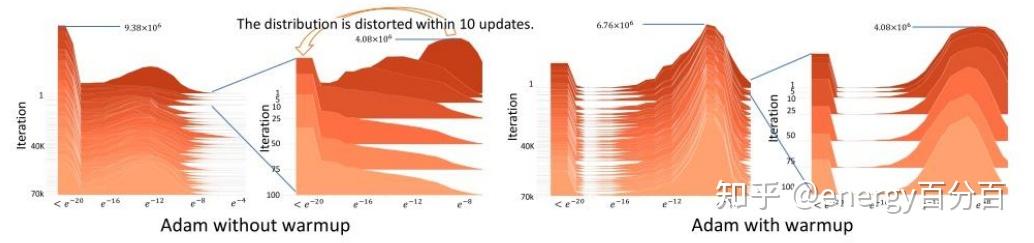
通过上图可知,没有使用warm-up的Adam算法,在算法初期(图二)梯度大小分布较为复杂(梯度数值跨度较大),而使用warm-up的Adam梯度值分布较为集中
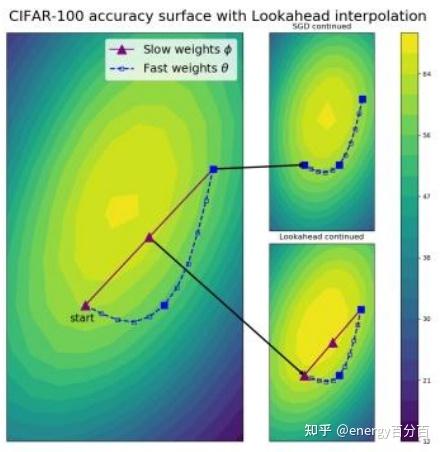
Lookahead(k step forward,1 step back)本质上是一种在各种优化器上层的一种优化器方法,内部可以使用任何形式的优化器,用作者的话说就是:universal wrapper for all optimizers
Lookahead 的就是:没使用优化器向前走k步,就对当前的第1步和第k步做一个加权平均(忽略中间的k-2步);以下图为例,蓝色线是优化器走的k步路径,然后将蓝线的起始点连接(图中红线),然后在红线上取一点作为k+1步的值(根据 α 而定)
Lookahead 的伪代码如下:
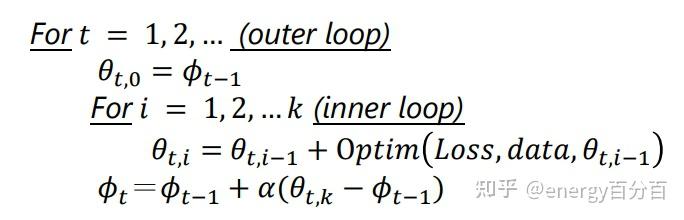
其中 optim() 为任意优化器得到的值
在神经网络中,为了提高网络的泛化性我们一般会在损失函数中增加 L2 正则,这种网络使用Adam和SGDM优化器会出现问题,关于正则化的相关知识请参考此文章:
energy百分百:#透彻理解# 机器学习中,正则化如何防止过拟合下图是三种优化器计算权重更新值的过程(损失函数中包含L2正则):
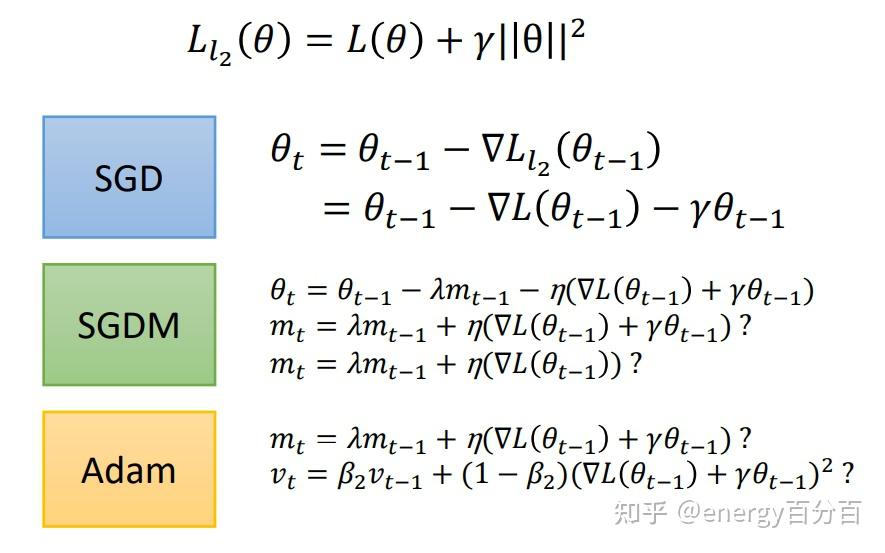
我们得到的
都多出了一个
,为了解决这个问题,2017年提出了 AdamW 和 SGDWM 优化器,这两种优化器将
放到了
和
外,AdamW 和 SGDWM 优化器的公式如下:
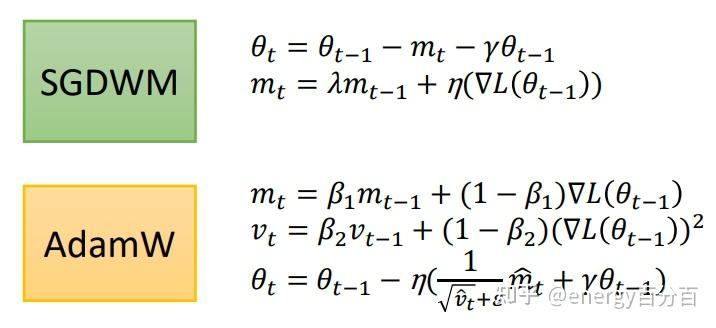
注:著名的Bert模型(PyTorch)中使用的 Adam优化器就是 AdamW优化器
SGDM 和 Adam 应用请参考下表:

文章首发于:
8A新闻
联系我们
公司名称: 8A-8A娱乐-注册登录商务站
手 机: 13800000000
电 话: 400-123-4567
邮 箱: admin@youweb.com
地 址: 广东省广州市天河区88号

